Introduction
Developer tools that are built in all modern browsers are powerful tools in a skillful hands. In this post I will show you how you can use
them (essentially javascript console) to parse web pages. If you are not familiar with any developer tools in web browsers, please read some introduction first.
You should also have basic knowledge of html, javascript and jquery.
I'll use Google Chrome as a web browser.
Idea
Basically in browsers javascript console we can execute javascript code in a context of current web page. Using ajax (XMLHttpRequest) we can also fetch html from nested
urls and parse them as well (like crawlers do). It isn't complicated or innovative, but there are two things that are worth mentioning.
-
I'll use jquery to produce smaller and easier code, because of its selectors and built-in ajax method. When page doesn't use that library already, we
need to inject it. It will be shown later in "Live example" how to do that.
- On ajax-based pages it's better to disable origin policy checking by web browser, because sometimes ajax requests will trigger origin
errors like "Origin http://www.example.com is not allowed by Access-Control-Allow-Origin".
In google chrome we can do it by executing it with --args --disable-web-security parameter. You can read more about origin policies here and here.
Basic example
I prepared really basic, static web page to demonstrate idea. The url is
http://cinu.pl/research/jsparsing/
Source code of this web page is:
index.html:
<html>
<head>
<script src="//ajax.googleapis.com/ajax/libs/jquery/1.10.2/jquery.min.js"></script>
</head>
<body>
<a href="a.html">link 1</a>
<a href="b.html">link 2</a>
<a href="c.html">link 3</a>
</body>
</html>
a.html,b.html,c.html contains a div with value we want to read:
<html>
<body>
<div class="container">
<div class="data">VALUE WE WANT TO FETCH</div>
</div>
</body>
</html>
As you can see in index.html there is already included jquery library so there is no need to inject it.
The parser code is:
var out = ''; // container for fetched values
function parse() {
$('a').each( // go through each anchor on page and make ajax request to fetch html
function(idx, item) {
var url = $(item).attr('href'); // get url
console.log('Fetching: '+ url); // debug note
// make ajax request (http://api.jquery.com/jQuery.ajax/)
$.ajax({
url: url,
async: false, // do it synchronously
}).done(function(data) { // data variable contains fetched html
var dataRetrieved = $('div',$(data)).html(); // get value we're looking for
console.log( 'Retrieved ' + dataRetrieved); // debug note
out += dataRetrieved + "\n"; // save retrieved value (+ separator)
});
}
);
console.log("-----------------\nParsing done, output:\n"+out); // print out parsed values
}
Go to
http://cinu.pl/research/jsparsing/, paste above code in Developer tools console and hit enter. To execute this code just write "parse()" and hit enter.
Result:
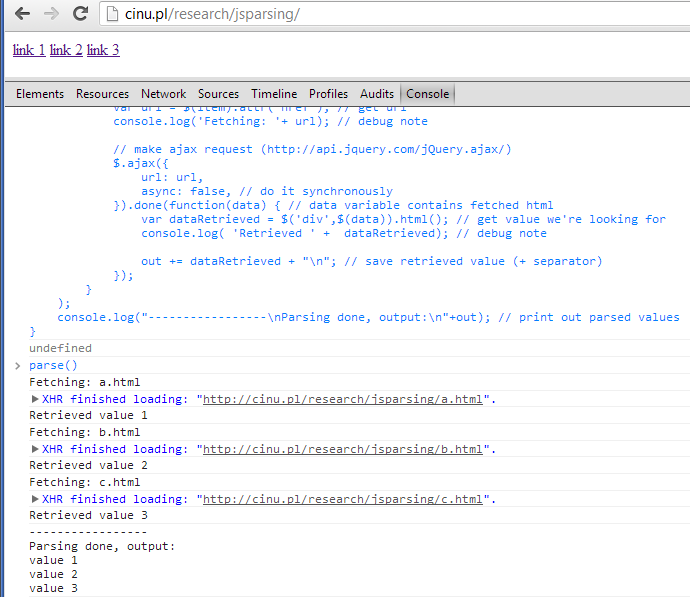
I guess this code is well documented, so there is no need to describe what it does, so lets try to do some more complicated example.
Live example - parsing aliexpress.com
The main goal is to fetch first 5 items from products category (I'll use
wireless routers as an example) and
check if there is any "feedback" from poland country on first page of feedback.
This task seems silly and
parsed data is rather useless but this is only example which helps me to utilize things I have previously written.
Step 1. Injecting JQuery
Since aliexpress doesn't use jquery we need to inject it.
Injection code:
var $jq; // jquery handler to avoid $ conflicts
function injectJquery() {
var script = document.createElement('script');
script.setAttribute('type', 'text/javascript');
script.setAttribute('src', '//ajax.googleapis.com/ajax/libs/jquery/1.10.2/jquery.min.js'); // fetch it from googles CDNs
// Give $ back to whatever took it before; create new alias to jQuery.
script.setAttribute('onload','javascript:$jq = jQuery.noConflict();');
document.body.insertBefore(script, document.body.firstChild);
}
injectJquery(); // call it automatically when paste into console
We can see that apart from simple injection we also make a
jQuery.noConflict() call and assign jquery to $jq and not $.
We need to do that because some scripts can also use $ (prototype.js for instance) and we need to give $ variable back to it because some parts
of javascript code on target page might be broken.
Step 2. Get urls of products we want to parse "feedback" on
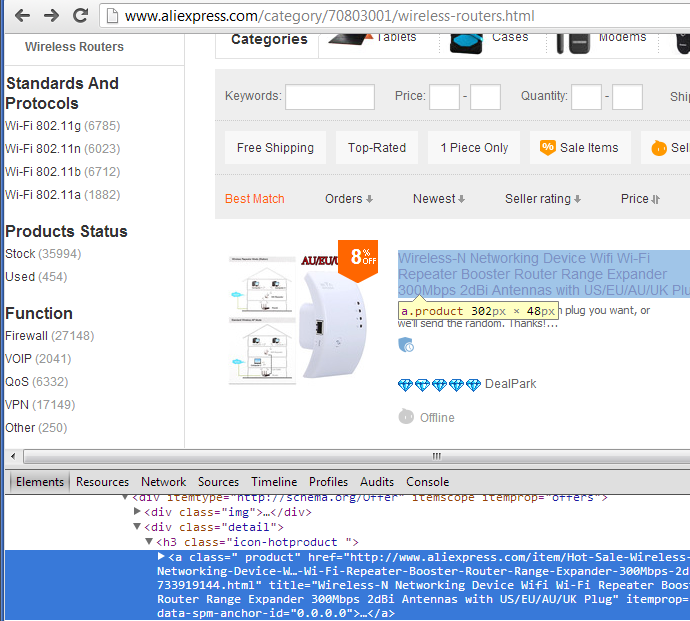
We need to remember that when we are fetching static pages through ajax, javascript won't be parsed and executed and we need do it manually. Because "Feedback"
tab is loaded dynamically with javascript we won't get "Feedback" data in html when we fetch product page. We will handle it in next step, for now parser code is:
var productsNum = 5;
function parse() {
var urls = $jq('a.product');
for(var i=0;i<productsNum && i<urls.length; i++) {
var url = $jq(urls[i]).attr('href'); // get url
console.log('Fetching: '+ url); // debug note
// make ajax request
$jq.ajax({
url: url,
async: false, // do it synchronously
}).done(function(data) { // data variable contains fetched html
var parsedDom = $jq(data);
// check if it works
console.log( '[TEST] item price: ' + $jq('#sku-price', parsedDom).html() );
});
}
}
Step 3. Find a way to fetch feedback (cause it's dynamically fetched through ajax).
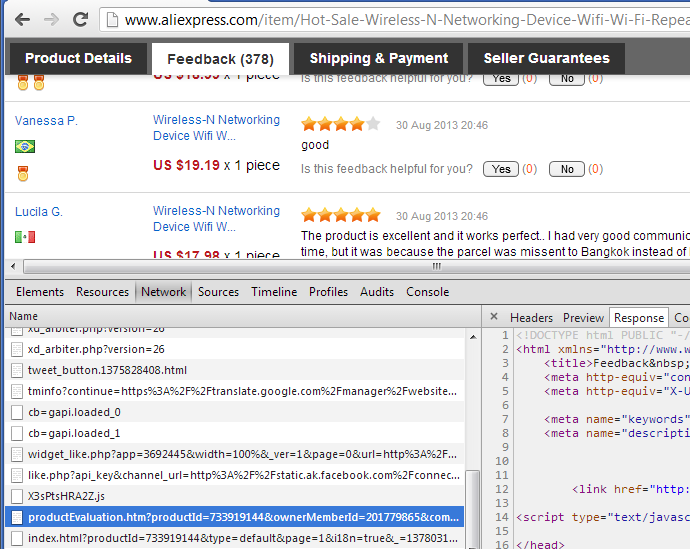
First of all we need to get url where http requests for feedback data goes. To do that we need to look in Network tab of Developer Tools, press "Feedback" tab on web page and
check "Documents" and "XHR" checkboxes (we don't need scripts, images, fonts etc.).
We can see couple of interesting urls like:
http://www.aliexpress.com/store/productGroupsAjax.htm?storeId=413596 [with JSON response]
http://www.aliexpress.com/findRelatedProducts.htm?productId=733919144&type=new [with JSON response]
But what we are looking for is:
http://feedback.aliexpress.com/display/productEvaluation.htm?productId=733919144&ownerMemberId=201779865&companyId=214347019&memberType=seller&startValidDate=&i18n=true
It contains raw HTML response. When we look into "response" we will see that this is exactly what are we looking for.
Now we need to take a closer look into parameters in url, that are:
productId=733919144
ownerMemberId=201779865
companyId=214347019
memberType=seller
startValidDate=
i18n=true
We can extract productId from product url for example in http://www.aliexpress.com/item/Hot-Sale-Wireless-N-Networking-Device-Wifi-Wi-Fi-Repeater-Booster-Router-Range-Expander-300Mbps-2dBi/733919144.html (product id is 733919144)
Only two of them are unknown: ownerMemberId and companyId. However if we look in the product page source code we will find it inside script tag:
...
window.runParams.adminSeq="201779865";
window.runParams.companyId="214347019";
...
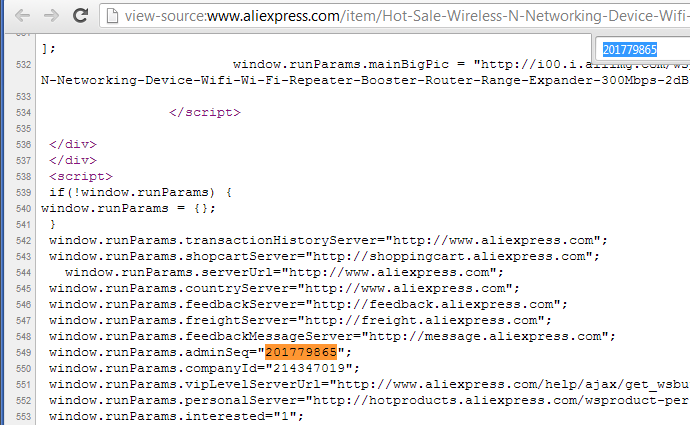
We need to get it directly from the html code. I'll use regular expressions:
...
var rx = /window.runParams.adminSeq="(\d+)"/g;
var arr = rx.exec(data); // data contains product page html
var adminSeq = arr[1];
var rx = /window.runParams.companyId="(\d+)"/g;
var arr = rx.exec(data); // data contains product page html
var companyId = arr[1];
console.log('Parsed runParams: ' + adminSeq + ' ' +companyId);
...
If you look closer you can see that productId is also in source code in window.runParams, so we will get it like adminSeq and companyId.
parse() function now looks like this:
var productsNum = 5;
function parse() {
var urls = $jq('a.product');
for(var i=0;i<productsNum && i<urls.length; i++) {
var url = $jq(urls[i]).attr('href'); // get url
console.log('Fetching: '+ url); // debug note
// make ajax request
$jq.ajax({
url: url,
async: false, // do it synchronously
}).done(function(data) { // data variable contains fetched html
//var parsedDom = $jq(data); // we dont need parsedDom since we will be executing regular expressions on raw html
// construct feedbackUrl:
var rx = /window.runParams.adminSeq="(\d+)"/g;
var arr = rx.exec(data); // data contains product page html
var adminSeq = arr[1];
var rx = /window.runParams.companyId="(\d+)"/g;
var arr = rx.exec(data); // data contains product page html
var companyId = arr[1];
var rx = /window.runParams.productId="(\d+)"/g;
var arr = rx.exec(data); // data contains product page html
var productId = arr[1];
var feedbackUrl = 'http://feedback.aliexpress.com/display/productEvaluation.htm?productId='+productId+'&ownerMemberId='+adminSeq+'&companyId='+companyId+'&memberType=seller&startValidDate=&i18n=true';
console.log('Feedback url: '+feedbackUrl);
// here we'll make another ajax call to fetch feedback data
});
}
}
4. Final step: Avoiding Origin policy checking and parse feedback html and check for searched country
If we try to make ajax call on prepared feedbackUrl in our parse() function we will see in console that "Origin http://www.aliexpress.com is not allowed by Access-Control-Allow-Origin" browser error.
In Google Chrome we can bypass it by adding --args --disable-web-security when we execute binary.
Looking into feedbacks html we can see that flag indicating users country is described as follows:
<span class="state"><b class="css_flag css_br"></b></span>
Simple jquery selector will do the job:
$jq('b.css_'+countryCode);
The final code is:
// jquery injection
var $jq; // jquery handler to avoid $ conflicts
function injectJquery() {
var script = document.createElement('script');
script.setAttribute('type', 'text/javascript');
script.setAttribute('src', '//ajax.googleapis.com/ajax/libs/jquery/1.10.2/jquery.min.js'); // fetch it from googles CDNs
// Give $ back to whatever took it before; create new alias to jQuery.
script.setAttribute('onload','javascript:$jq = jQuery.noConflict();');
document.body.insertBefore(script, document.body.firstChild);
}
injectJquery();
// parsing
var productsNum = 5;
function parse(country) {
var urls = $jq('a.product');
for(var i=0;i<productsNum && i<urls.length; i++) {
var url = $jq(urls[i]).attr('href'); // get url
console.log('Fetching: '+ url); // debug note
// make ajax request
$jq.ajax({
url: url,
async: false, // do it synchronously
}).done(function(data) { // data variable contains fetched html
//var parsedDom = $jq(data); // we dont need parsedDom since we will be executing regular expressions on raw html
// construct feedbackUrl:
var rx = /window.runParams.adminSeq="(\d+)"/g;
var arr = rx.exec(data); // data contains product page html
var adminSeq = arr[1];
var rx = /window.runParams.companyId="(\d+)"/g;
var arr = rx.exec(data); // data contains product page html
var companyId = arr[1];
var rx = /window.runParams.productId="(\d+)"/g;
var arr = rx.exec(data); // data contains product page html
var productId = arr[1];
var feedbackUrl = 'http://feedback.aliexpress.com/display/productEvaluation.htm?productId='+productId+'&ownerMemberId='+adminSeq+'&companyId='+companyId+'&memberType=seller&startValidDate=&i18n=true';
// get feedback page and check if there is searched country
$jq.ajax({ // to make that request we need to disable web security in google chrome
url: feedbackUrl,
async: false,
}).done(function(data) {
console.log( $jq('b.css_'+country, $jq(data)).length );
// check if element with css_country class exists:
if ( $jq('b.css_'+country, $jq(data)).length ) {
console.log('[FOUND] item: '+url);
}
});
});
}
}
We executing it with parse('pl') when we want to check if there is a feedback from poland.
Some thoughs
In above example we made operations on a raw html code, however using json is a lot easier, because we don't need to use regular expressions, jquery selectors, etc. to fetch data.
Another thing is that we don't need to store data in console log. We can inject some div into webpage and then store results in it.




{kind=link}